Embodied navigation is a fundamental capability of embodied intelligence, enabling robots to move and interact within
physical environments. However, existing navigation tasks
primarily focus on predefined object navigation or instruction
following, which significantly differs from human needs in
real-world scenarios involving complex, open-ended scenes.
To bridge this gap, we introduce a challenging long-horizon
navigation task that requires understanding high-level human
instructions and performing spatial-aware object navigation
in real-world environments. Existing embodied navigation
methods struggle with such tasks due to their limitations in
comprehending high-level human instructions and localizing
objects with an open vocabulary. In this paper, we propose
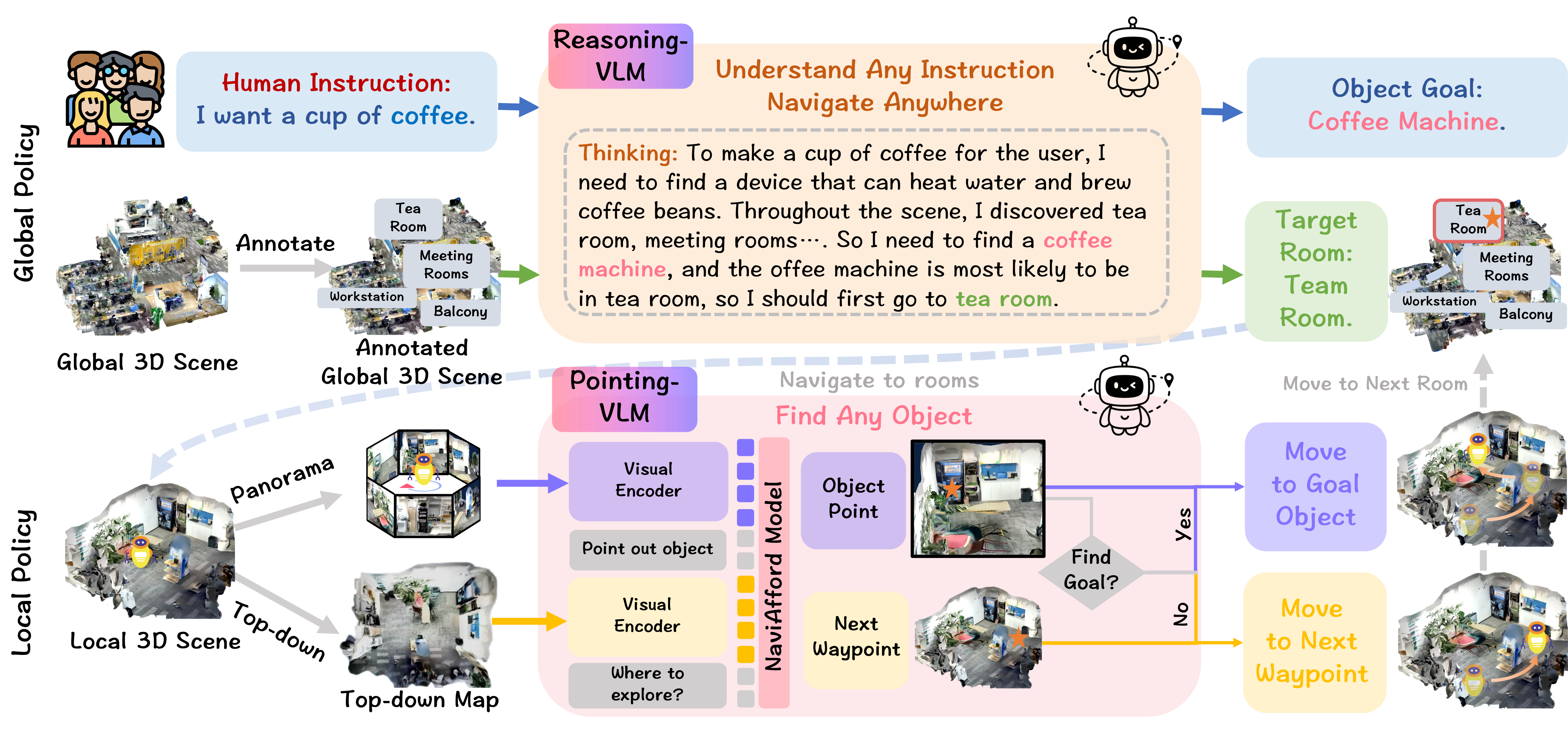
\(NavA^3\), a hierarchical framework divided into two stages:
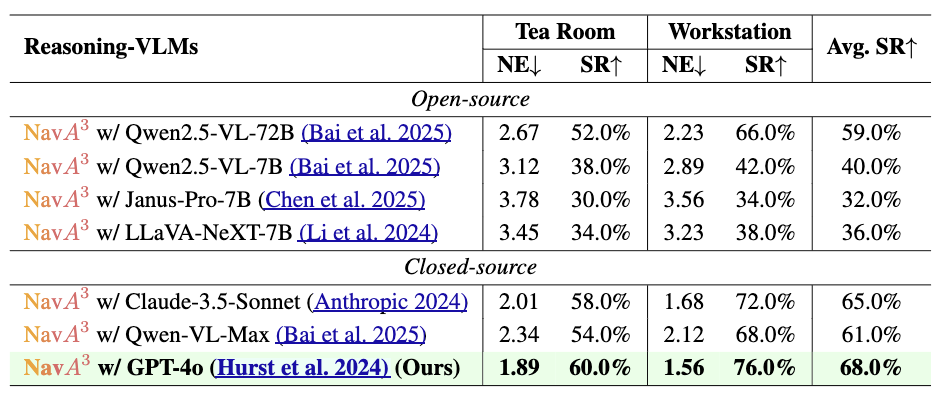
global and local policies. In the global policy, we leverage the
reasoning capabilities of Reasoning-VLM to parse high-level
human instructions and integrate them with global 3D scene
views. This allows us to reason and navigate to regions most
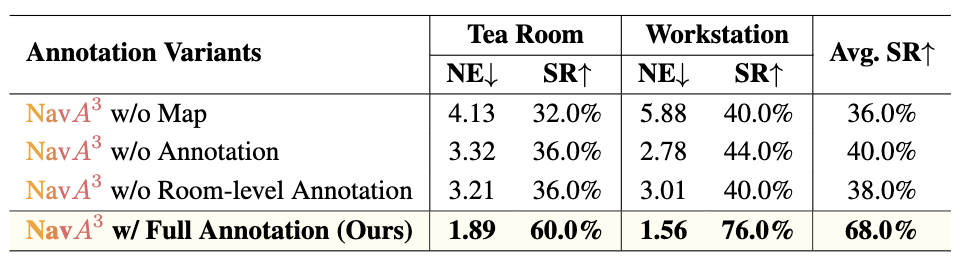
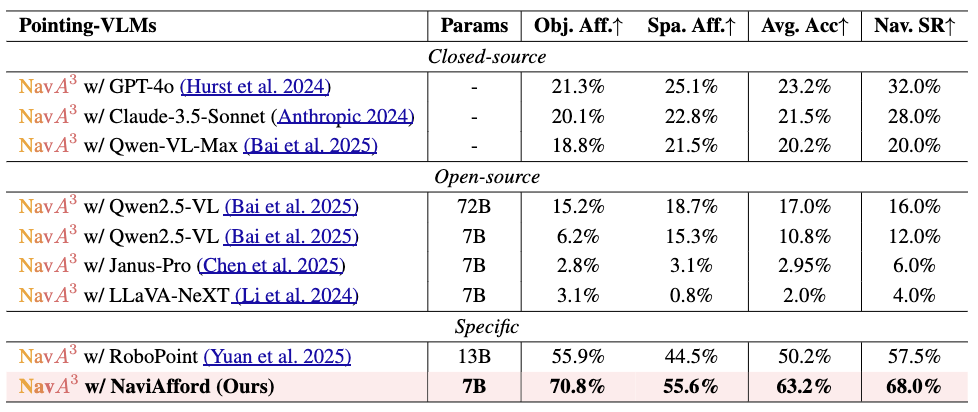
likely to contain the goal object. In the local policy, we have
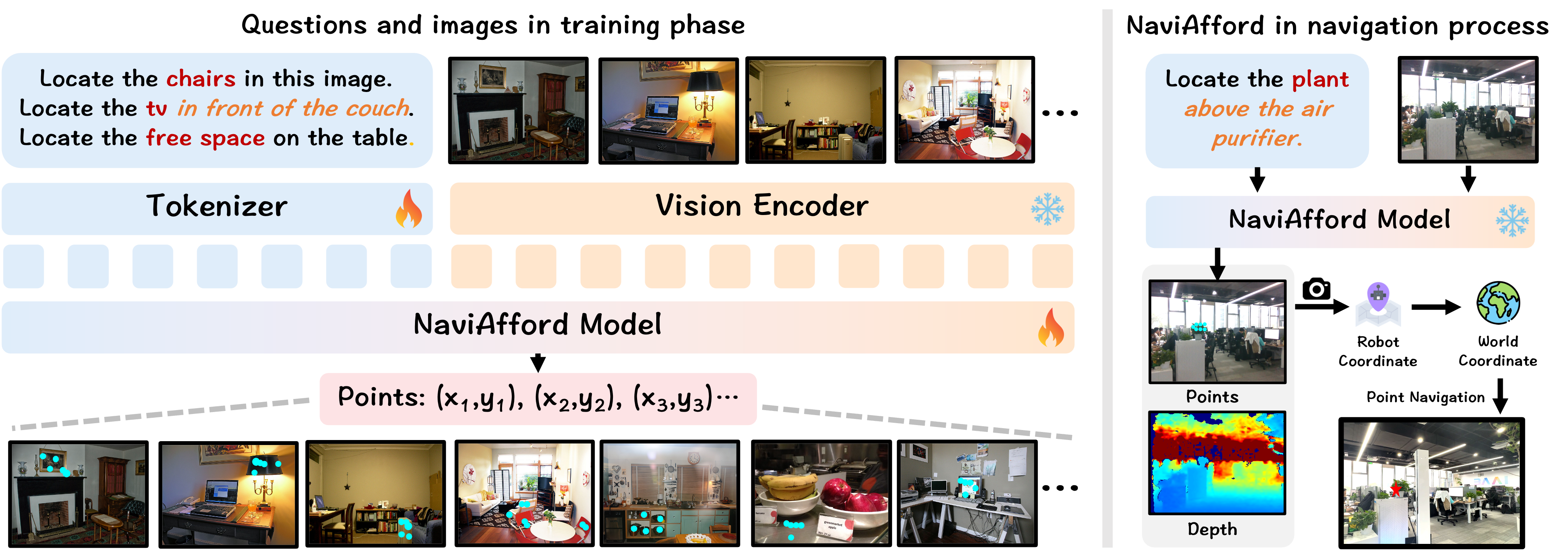
collected a dataset of 1.0 million samples of spatial-aware
object affordances to train the NaviAfford model (PointingVLM), which provides robust open-vocabulary object localization and spatial awareness for precise goal identification
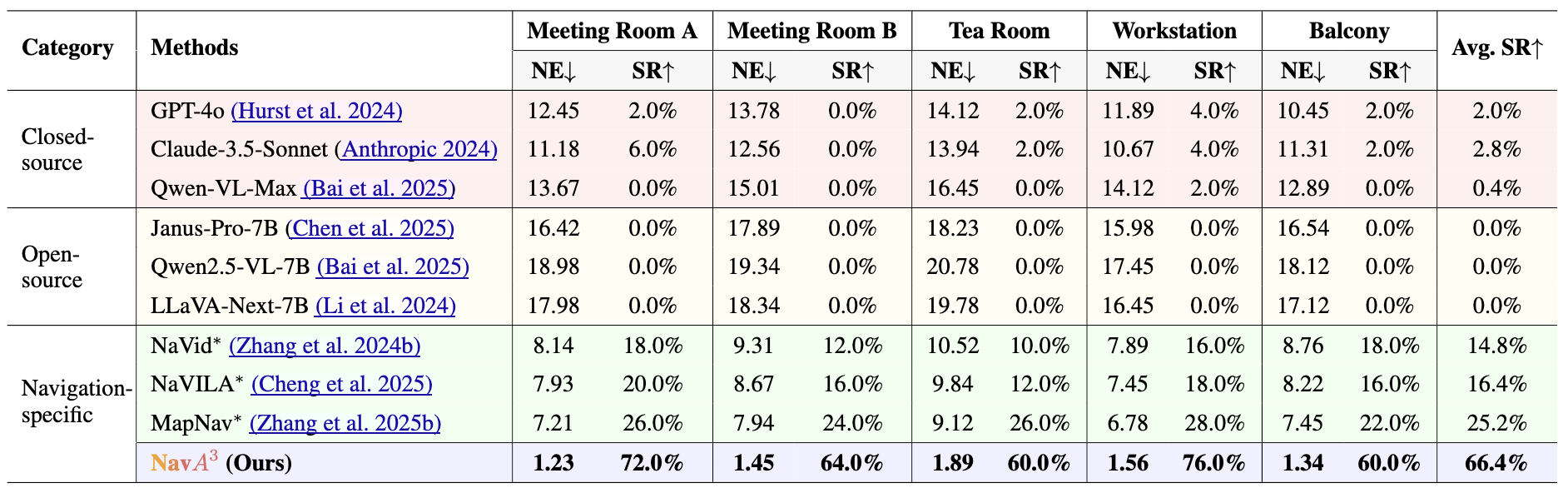
and navigation in complex environments. Extensive experiments demonstrate that \(NavA^3\) achieves SOTA results in
navigation performance and can successfully complete longhorizon navigation tasks across different robot embodiments
in real-world settings, paving the way for universal embodied
navigation. The dataset and code will be made available